本文共 2002 字,大约阅读时间需要 6 分钟。
NTT 是一家全球电信公司,总部设在日本东京。在《财富》世界 500 强中,NTT 是世界第四大电信公司。NTT 通信 (NTT Com) 是 NTT 的子公司,其全球 IP 网络 (GIN) 业务部拥有并运营着全球最大的一级 IP 骨干网之一,为欧洲、北美、南美、亚洲、大洋洲等主要国家提供高速、高容量的 IP 通信服务。
任何互联网主干的核心活动之一都是流量分析,它支持对许多技术方面 (容量规划、流量工程等)、经济方面(资源优化、收入泄漏检测等) 和安全用例的全球流量进行可视化分析。NTT GIN 的流量分析以 “流量矩阵” 为中心,它表示给定 Internet 域中所有可能的源和目的地对之间的所有流量。通过为这些数据提供实时流量可视化和快速解释的能力,我们为整个组织释放了巨大的商业价值。
NTT GIN 遗留的流量分析系统存在以下几个问题:
- 这是一个黑盒子,很难进行故障排除并扩展以添加新功能,无论是在后端还是前端。
- 它没有以经济高效的方式进行扩展。
- 特定分析能力有限,而这对于快速理解数据异常而言非常重要。
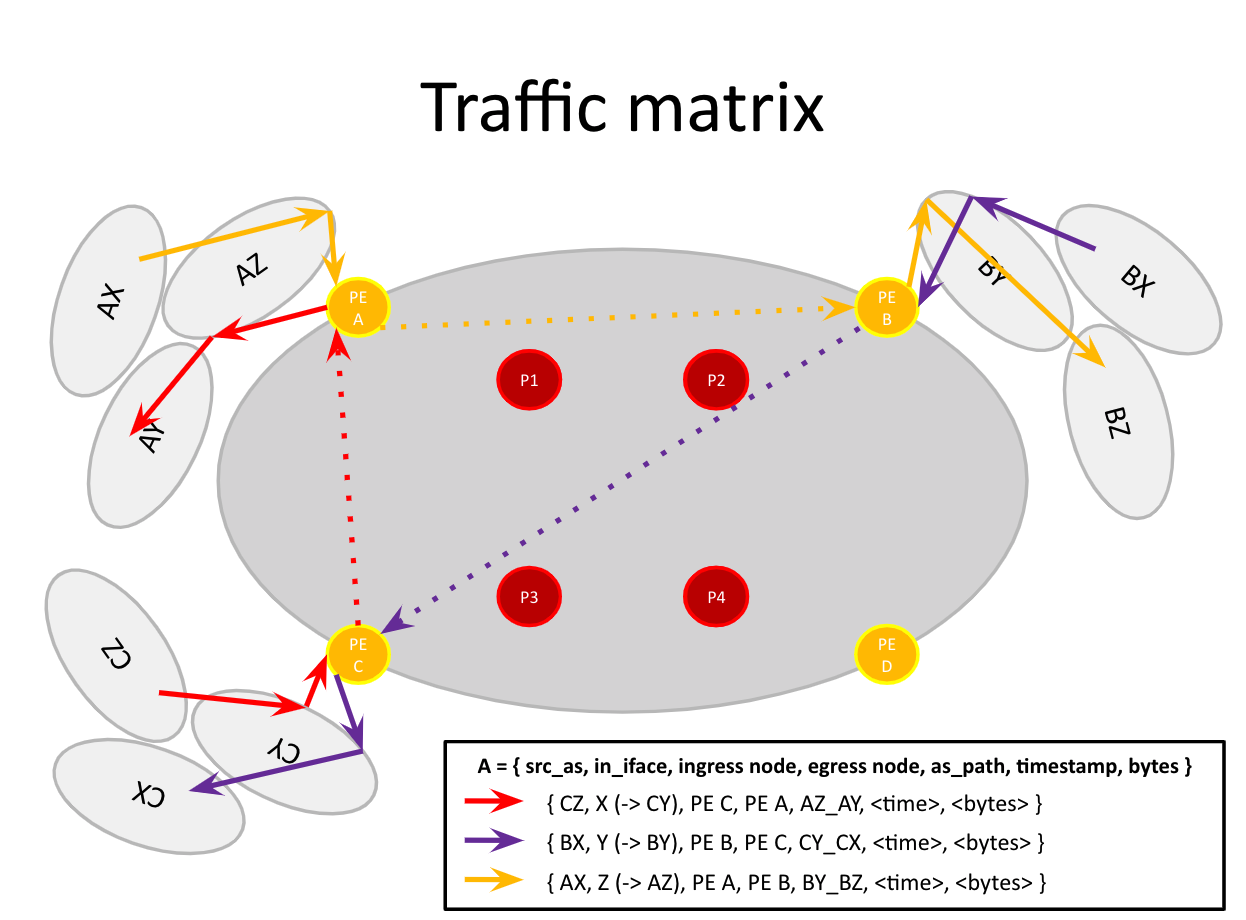
当我们考虑对技术设施进行现代化改造时,我们评估了新构建流量分析的解决方案,而不是购买现有产品。因为我们注意到现有产品中的主要问题是,没有一款产品能够精确匹配我们的需求。要知道我们是一家规模庞大的公司,需要大量定制功能来进行流量分析,尽管有些产品确实包含了允许我们进行扩展的 API,但仍然面临着两个问题:产品的高成本,以及扩展产品所需的工程资源数量。如果我们要投入工程资源的话,就需要更多的灵活性和控制力,因此,我们决定构建一个解决方案。
当我们开始评估解决方案时,我们将重点放在能够扩展到我们的数据量的技术(即 “大数据” 技术)上,并测试了我们想要构建的新堆栈的每个部分的各种替代方案。最终,我们确定了一种设计,其中我们的核心架构将包含两个组件:用于从流量矩阵传递数据的事件总线,以及用于收集、存储和分析这些数据的查询系统。一组由工程师组成的团队对数据管道的不同部分进行了评估。经过深入评估之后,我们选择了 Apache Kafka 作为事件总线,部分原因是由于它在内部测试期间所展现出来的可扩展性、可靠性及性能。而查询系统则选择了 Apache Druid。尽管有许多开源和商业解决方案可供选择,但我们对 Druid 在内部测试时的表现印象特别深刻。与面向日志搜索 / 面向文档的数据库相比,我们发现,Druid 在大规模分析方面更高效,而且与时间序列数据库相比,在接受、存储和查询相同数量的数据时,所需的资源更少。特别是 Druid 在提供非时间维度的SQL GROUP BY和WHERE查询方面非常出色,而这正是对我们的流量矩阵进行特定分析的重要功能。
除了 Druid 的查询功能之外,它最重要的特点之一就是能够与 Kafka 进行本地集成。Druid 可以从 Kafka 精确地使用一次数据,并允许我们构建完整的端到端流分析堆栈。这种类型的体系结构成为 Kappa 体系架构,最初是在博文 Questioning the Lambda Architecture(《Lambda 架构的问题》)提到的。NTT GIN 是世界上最早在实践中实施这种创新体系架构的公司之一,到目前为止,它不仅解决了我们传统解决方案的问题,还让我们得以能够在此前从未有过的数据探索中创建新用例。为完成我们堆栈,我们与 Druid 幕后的公司 Imply 合作,并利用他们的 Pivot UI 进行数据分析。Pivot 易于进行特定分析。通过简单地拖放数据库维度来生成各种特定可视化,非常简单,这点对我们理解异常数据模式而言至关重要。
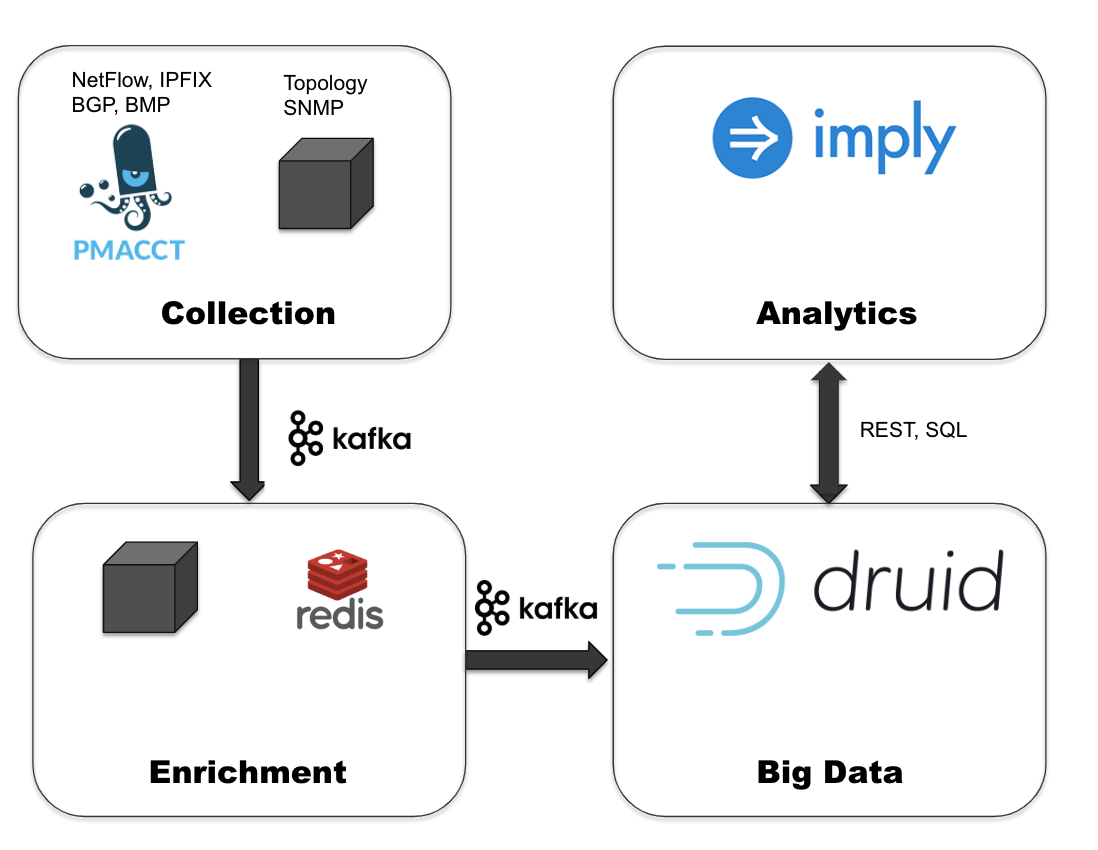
现在,我们的新栈在生产环境中运行,每秒接收超过 10 万次事件。虽然大多数 UI 工具(尤其是以流量为中心的 UI 工具)仅针对一类用户设计:通常用于操作(容量分析)、工程(直接分析流量矩阵),或开发中。但我们通过 Kafka、Druid、Imply 的 Pivot 的解决方案,能够使组织中许多不同级别的用户能够自由探索数据,而不会限制他们访问预定义仪表板。用户已经掌握了用于容量分析、流量矩阵分析和域间流量分析(对等分析)的新用例。用户还可以创建自己的自定义仪表板,并在不同团队中自由分享见解。
通过为网络流量分析奠定坚实的基础,并为基础设施 / 拓扑数据、转发平面数据和控制平面数据提供单一环境,我们现在计划扩展工作范围,并添加更多信息源来关联数据。这包括用于主动测量的数据(翻翻时间、抖动、数据包丢失等)、网络路径质量,以及用于域间撸油安全分析的 RPKI/ROA 验证,这对于第一层网络骨干网的全球互联网的稳定性来说,至关重要。
如果你遇到与我们类似的情况,我们强烈建议你去了解 Apache Druid 和 Apach Kafka。
原文链接:
转载地址:http://wfvix.baihongyu.com/